The April 2026 frontier-model wave: DeepSeek-V4, Qwen3.5-Omni, GPT-5.5, Claude Opus 4.7 & four more.
TL;DR
Focus
The first cold-start review covers the densest stretch of frontier-model launches we have on record: eight new flagships landed between April 12 and April 30, 2026, from labs spread across three continents. DeepSeek-V4 (Apr 24) and Qwen3.5-Omni (Apr 17) shipped with full arXiv technical reports; OpenAI's GPT-5.5 (Apr 23) shipped with a Preparedness-framework system card; Anthropic's Claude Opus 4.7 (Apr 16), Moonshot's Kimi K2.6 (Apr 20), MiniMax M2.7 (Apr 12 open weights), xAI's Grok 4.3 (Apr 30), and Mistral Medium 3.5 (Apr 30) shipped as launch posts or model cards. Three threads cut across all eight: long-context as table stakes (1M tokens at DeepSeek, Grok, and Qwen; 256k–262k at MiniMax, Mistral, Moonshot), agentic coding as the unified evaluation target (SWE-Bench Verified / Pro and Terminal-Bench 2.0 are now the universal scoreboard), and open-weights pricing compression from the Chinese labs.
Competitiveness
Claude Opus 4.7 holds the SWE-Bench Verified frontier at the time of writing, with DeepSeek-V4-Pro-Max trailing by 0.2 points (80.6%) at a small fraction of the inference cost, and Mistral Medium 3.5 closing to 77.6% on a 128B dense model. GPT-5.5 leads OpenAI-internal Preparedness-style biology and cyber evals. Grok 4.3 is the price/performance shock — a roughly 40% input / 60% output price cut versus Grok 4.20 lifts it onto the Intelligence Index just above Muse Spark and Claude Sonnet 4.6. On audio and audio-visual understanding, Qwen3.5-Omni-plus passes Gemini 3.1 Pro in 215-task aggregates. The closed Western frontier (Opus 4.7, GPT-5.5, Gemini 3.1 Pro from February, Grok 4.3) still leads on the hardest reasoning and agentic benchmarks; the open Chinese frontier (DeepSeek-V4, Kimi K2.6, MiniMax M2.7) has converged onto the same capability ceiling on agentic coding at roughly a third of the inference cost.
New frontier releases
Eight flagship models shipped in 19 days: MiniMax M2.7 open weights (Apr 12), Claude Opus 4.7 (Apr 16), Qwen3.5-Omni (Apr 17 arXiv), Kimi K2.6 (Apr 20), GPT-5.5 (Apr 23), DeepSeek-V4 (Apr 24), Grok 4.3 and Mistral Medium 3.5 (both Apr 30).
Alibaba (Qwen)
Qwen3.5-Omni Technical Report
Overview
- Successor to Qwen2.5-Omni in the Thinker–Talker family. Scales to hundreds of billions of parameters, supports a 256k context window, and trains on a mix of heterogeneous text–vision pairs and over 100M hours of audio-visual content.
- Headline claim: Qwen3.5-Omni-plus reaches SOTA across 215 audio and audio-visual understanding / reasoning / interaction subtasks, surpassing
Gemini-3.1 Proin key audio tasks and matching it in comprehensive audio-visual understanding. - Five named contributions: Hybrid-Attention MoE in both Thinker and Talker; 256k context modeling; multi-codebook codec representation for immediate single-frame synthesis; ARIA streaming text–speech alignment; 113-language ASR / 36-language TTS coverage.
- The authors report a surprise emergent behavior they call Audio-Visual Vibe Coding: the model writes code directly from audio-visual instructions (e.g., a screen recording with spoken intent) without a text intermediary.
Architecture
- Problem the Hybrid-Attention MoE solves. Pure dense attention costs scale quadratically with context; pure MoE without an attention rework still bottlenecks on KV-cache size at 256k, especially when audio tokens (which arrive at high rates from 100M hours of audio-visual pretraining) inflate sequence length.
- Mechanism. Both halves of the Thinker–Talker stack use the same Hybrid-Attention MoE block: dense softmax attention on a compressed key-value stream is interleaved with sparse / linear attention paths, while the FFN is replaced with a Mixture-of-Experts router. The Thinker handles cross-modal reasoning; the Talker handles speech-token generation conditioned on Thinker hidden states.
- Why it works / why it beats prior. Compared with the dense Talker in Qwen2.5-Omni, gating expert activation per token lets the Talker carry far more speech-knowledge parameters without paying for them at inference; combined with the compressed-KV path, it cuts latency on 10-hour audio understanding to the point where streaming inference is practical.
- The Thinker accepts text, image, audio, and audio-visual inputs natively, and the Talker can drive 400-second 720p video understanding at 1 FPS.
Pre-training
- Pre-training corpus mixes heterogeneous text–vision pairs with over 100M hours of audio-visual content. The paper does not disclose total token counts in the abstract.
- Multilingual coverage: 113 languages for ASR, 36 for TTS, all jointly trained end-to-end (no separate per-language models).
Post-training
- ARIA — Adaptive Real-time Interleaved Alignment.
- Problem. Streaming text-to-speech is unstable and unnatural because text tokenizers and speech tokenizers run at different effective rates — a single text token can span many speech frames, and naive interleaving either stalls speech output (waiting for text context) or produces speech that drifts ahead of the planned text and clips off prosody cues at sentence boundaries.
- Mechanism. During streaming decoding, ARIA dynamically picks, at each step, whether the model should emit the next speech codec token, consume the next text token, or pull more context from upstream cross-attention. The decision is conditioned on the running prosody prediction and the residual text buffer — not on a fixed text-to-speech rate ratio.
- Why. Beats fixed-rate interleaving because the rate adapts to the actual content (short interjections finish early, long clauses get more text lookahead). Latency impact is reportedly minimal because the model does not have to backtrack on emitted speech tokens.
- Multi-codebook codec representation. Audio output uses a multi-codebook neural codec rather than a single VQ codebook. Each speech frame is represented by parallel codes from N codebooks, so a single decoder forward pass emits a complete frame instead of N sequential autoregressive steps. This is what makes "single-frame, immediate synthesis" feasible.
Evaluation & Results
- SOTA on 215 audio and audio-visual subtasks aggregated across the standard benchmark suites.
- Surpasses Gemini 3.1 Pro on a set of key audio tasks; ties or matches Gemini 3.1 Pro on comprehensive audio-visual understanding.
- Supports 10+ hours of single-context audio understanding (limited by 256k context with audio tokenization rates the report does not fully break down).
- Speech generation across 10 languages with explicit emotional prosody control.
- Audio-visual grounding: produces script-level structured captions with temporal synchronization and automated scene segmentation.
Availability
- Technical report on arXiv (CC-BY 4.0); model weights and checkpoints distributed through the Qwen org on Hugging Face per Qwen Team launch convention.
Anthropic
Introducing Claude Opus 4.7
Overview
- Direct upgrade to Claude Opus 4.6, released the same day Anthropic acknowledged a more capable internal model (Claude Mythos Preview) and stated Opus 4.7 is the first model on which the new Cyber Verification Program and automated cyber-misuse blocks are being tested at scale.
- API id:
claude-opus-4-7. Pricing unchanged from Opus 4.6 at $5 / $25 per million input / output tokens. Available on the Claude API, Amazon Bedrock, Vertex AI, and Microsoft Foundry from launch day. - The launch post discloses no architecture or parameter count. Most disclosed gains are qualitative (instruction following, multimodal fidelity, long-horizon coherence) plus a partner-quoted spread of internal benchmark deltas.
Architecture
- Not disclosed. Anthropic's launch posts have not disclosed parameter counts, attention variant, or MoE / dense structure for any model since Claude 3.
- One implementation-level change is disclosed: Opus 4.7 ships with an updated tokenizer. The same input now produces roughly 1.0×–1.35× more tokens than under Opus 4.6, depending on content type — Anthropic recommends measuring token impact on real traffic before migrating.
Post-training
- Anthropic introduces a new xhigh effort level between
highandmax. Effort levels in the Claude API control how many internal reasoning tokens the model spends per response; xhigh is positioned as a finer-grained option for hard agentic and coding tasks. Claude Code's default effort level has been raised to xhigh for all plans. - Substantially better instruction following is the dominant qualitative claim — Anthropic flags that prompts tuned for Opus 4.6 may now produce unexpected results because Opus 4.7 takes instructions more literally and skips parts less often.
- Cyber safeguards are differentially applied: during training Anthropic experimented with techniques to reduce cyber-capability differentially relative to other capabilities, then ships Opus 4.7 with runtime classifiers that detect and block prohibited or high-risk cyber requests. Security researchers can join a Cyber Verification Program to lift those blocks for legitimate vulnerability / pen-test work.
Evaluation & Results
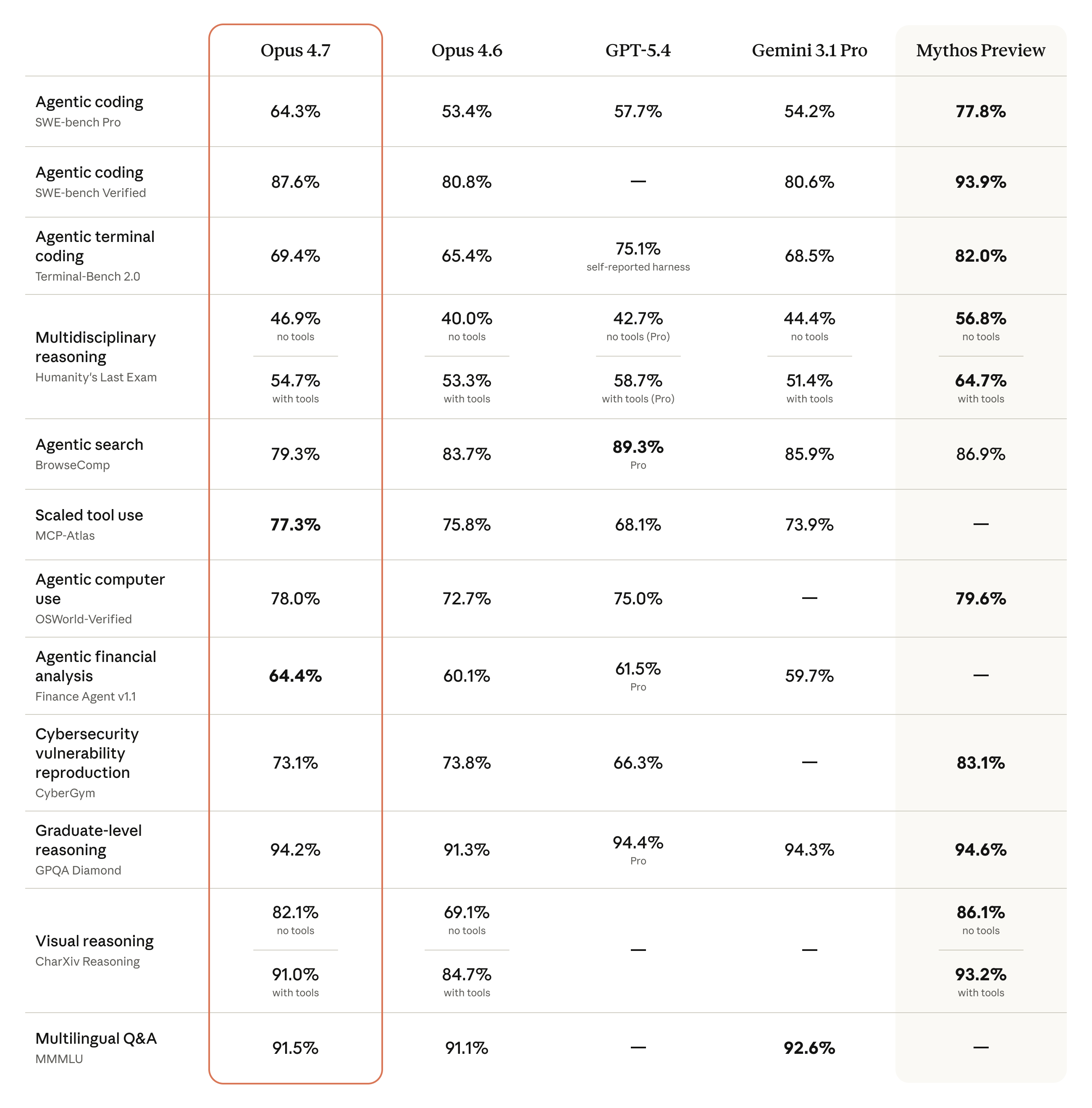
- SOTA on Finance Agent (third-party); SOTA on GDPval-AA, the third-party knowledge-work eval across finance and legal.
- Substantial visual fidelity bump: Opus 4.7 accepts images up to 2,576 pixels on the long edge (~3.75 MP), roughly 3× the prior limit. Partner XBOW reports a benchmark jump from 54.5% (Opus 4.6) to 98.5% (Opus 4.7) on their internal visual-acuity test, the largest single-task delta in any quoted external eval.
- Partner-quoted deltas: GitHub reports +13% on a 93-task internal coding benchmark; Cursor reports CursorBench moving from 58% (Opus 4.6) to 70%+ (Opus 4.7); Harvey reports 90.9% at high effort on BigLaw Bench; Databricks reports 21% fewer errors on OfficeQA Pro.
- SWE-bench notes: Anthropic flags that their memorization screens detect a subset of contaminated problems in SWE-bench Verified / Pro / Multilingual; the relative margin of Opus 4.7 over Opus 4.6 holds when those problems are excluded.
- Terminal-Bench 2.0 reported using the Terminus-2 harness with thinking disabled, 1× / 3× guaranteed / ceiling resources, averaged over five attempts.
Safety & Limitations
- Anthropic's alignment assessment concludes Opus 4.7 is "largely well-aligned and trustworthy, though not fully ideal in its behavior." On their automated behavioral audit, the overall misaligned-behavior score is modestly below Opus 4.6 and Sonnet 4.6, but still higher than Mythos Preview.
- Improvements over 4.6 on honesty and prompt-injection resistance. Regression: more willing to give detailed harm-reduction advice on controlled substances.
- Token usage caveat is non-trivial: combined with the new tokenizer expansion and heavier thinking at higher effort levels, real-traffic token usage typically rises, though Anthropic's own coding evaluation reports favorable accuracy-per-token at every effort level.
Availability
claude-opus-4-7on the Claude API, Amazon Bedrock, Vertex AI, Microsoft Foundry. Three free/ultrareviewsessions in Claude Code for Pro and Max plans. Auto mode for Claude Code extended to Max users.- Task budgets in public beta on the Claude Platform — a developer-facing knob for guiding Claude's token spend across long agentic runs.
DeepSeek
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Overview
- Two Mixture-of-Experts models:
DeepSeek-V4-Proat 1.6T total / 49B active parameters andDeepSeek-V4-Flashat 284B total / 13B active. Both expose a 1M-token context and a 384k-token max output length. Both are MIT-licensed. - Retains the DeepSeekMoE framework and Multi-Token Prediction (MTP) head from DeepSeek-V3, then rebuilds the attention stack and the post-training pipeline.
- Headline efficiency claim: at the 1M-token operating point, V4-Pro requires 27% of the per-token inference FLOPs and 10% of the KV-cache footprint of DeepSeek-V3.2.
- Named contributions: Compressed Sparse Attention (CSA), Heavily Compressed Attention (HCA), a CSA + HCA hybrid layer interleaving scheme, and a two-stage SFT + GRPO + On-Policy Distillation post-training pipeline.
Architecture
- Compressed Sparse Attention (CSA).
- Problem. Standard MHA at 1M context is dominated by the O(n²) softmax cost and an enormous KV cache. Pure sliding-window attention or linear attention scales but loses the sharp retrieval behavior that's load-bearing for long-context coding and tool use.
- Mechanism. CSA layers run in two stages per query. (1) The full sequence's KVs are bucketed into windows of m=4 tokens; each window is collapsed to a single compressed (K, V) entry via a softmax-gated pooling head with a learned positional bias, giving 4× compression along the sequence dimension. (2) A "lightning indexer" — an FP4 multi-head dot-product scorer with a ReLU on top — picks the top-k compressed blocks per query. Sparse softmax attention then runs only over those k entries.
- Why. Keeps the sharp top-k retrieval behavior of full softmax MHA, but on a 4× compressed grid attended sparsely — so the per-query attention cost collapses from O(n) (with KV-cache reads) to O(k). Beats prior sparse-attention designs (block-sparse, Longformer-style window+global) because the compressed indexer learns which compressed blocks matter, rather than imposing a fixed sparsity pattern.
- Heavily Compressed Attention (HCA).
- Problem. Even with CSA, every layer paying for a top-k softmax search at 1M tokens is too expensive at decode time, and you still want some path that sees the whole context for broad semantic routing.
- Mechanism. HCA layers compress KV more aggressively along the sequence axis, producing a much smaller global summary stream that all queries can attend to densely.
- Why. CSA preserves retrieval sharpness in the layers where you need it; HCA reclaims linear-ish global context everywhere else. Layer-wise interleaving means the model can do fine-grained retrieval in some layers and broad global routing in others, all in one stack.
- Multi-Token Prediction (MTP) head from V3 is retained — at decode time the model predicts the next k tokens jointly, used for self-speculation acceleration.
Pre-training
- The V4 series upweights code and high-quality textbook data versus V3.2's mix; total token counts are not disclosed in the public model card.
- Both V4-Pro and V4-Flash are pre-trained with the same hybrid CSA + HCA stack from scratch (not a V3 continuation training), enabling the 1M context to be a first-class objective rather than a post-hoc extension.
Post-training
- Two-stage SFT → GRPO → On-Policy Distillation pipeline.
- Problem. Multi-domain RL post-training (math, code, agentic tool use, chat) tends to interfere — improvements in one domain regress another. Standard off-policy distillation from a stronger teacher also struggles when the student's distribution diverges from the teacher's outputs.
- Mechanism. Stage 1 runs supervised fine-tuning, then GRPO (Group Relative Policy Optimization) — DeepSeek's PPO-replacement where multiple completions per prompt give group-relative advantage estimates and the critic is removed entirely. Stage 2 runs On-Policy Distillation: the student model generates rollouts first, then learns from teacher feedback graded on those rollouts, rather than imitating teacher-generated trajectories.
- Why. Removing the critic in GRPO drops memory and compute roughly 50% versus PPO, which is what makes the on-policy second stage affordable at this scale. OPD avoids the distribution-shift trap of off-policy distillation (where the student tries to imitate trajectories it would never generate) and lets the teacher act as a per-step reward signal instead of a behavior cloner.
Evaluation & Results
- V4-Pro-Max headline numbers on agentic coding and reasoning benchmarks:
| Benchmark | DeepSeek-V4-Pro-Max | Reference |
|---|---|---|
| SWE-Bench Verified | 80.6% | Trails Claude Opus 4.6 by 0.2 points |
| SWE-Bench Pro | 55.4% | Frontier band |
| LiveCodeBench | 93.5 | Frontier band |
| MMLU-Pro | 87.5% | Strong general |
| GPQA Diamond | 90.1% | Strong reasoning |
- Efficiency: at 1M tokens, single-token inference cost is 27% of V3.2's FLOPs; KV cache is 10% of V3.2's footprint. This is the entire reason CSA + HCA exists.
Availability
- Both
DeepSeek-V4-ProandDeepSeek-V4-Flashon Hugging Face under MIT license. Available via the DeepSeek API.
MiniMax
MiniMax M2.7: Early Echoes of Self-Evolution
Overview
- First hosted as a March 18 release; open-weights drop on Hugging Face followed on Apr 12, 2026 — the event that brings it into our window.
- 230B-parameter MoE with 10B active per token, 256 experts, 200k context. Text-only; an "M2.7-highspeed" variant trades quality for latency.
- Headline claim: M2.7 is the first MiniMax model to "deeply participate in its own evolution" — an internal version autonomously ran 100+ optimization rounds (analyze failures → modify code → evaluate → keep / revert), reportedly producing a 30% improvement on internal programming benchmarks.
Architecture
- 230B total / 10B active MoE, 256 experts. 200k context window. The model card does not detail the routing function, expert imbalance handling, or attention variant beyond "MoE with lightning attention" carried over from the M2 line.
Post-training
- Self-evolution loop.
- Problem. Manual RL post-training requires human researchers to (i) write task evaluators, (ii) propose code / recipe edits, and (iii) decide which changes to keep — three loops that don't scale with model count or task count.
- Mechanism. An internal "researcher" instance of M2.7 runs an outer optimization loop in autonomy: it analyzes failure trajectories from prior training runs, proposes edits to training code (data filters, RL recipes, reward terms), runs short evaluation cycles, and decides keep / revert against an internal benchmark. 100+ rounds reportedly ran without human gating.
- Why. Beats human-supervised RL recipe search on internal programming benchmarks (claimed +30%) because the researcher instance can iterate at machine timescales; the question of whether the gains transfer beyond MiniMax's eval suite is the obvious open one.
- RL across "hundreds of thousands" of real-world environments (coding, tool use, search, office workflows) — the same dataset philosophy as M2.5 but expanded.
Evaluation & Results
- SWE-Bench Pro: 56.22%. Terminal-Bench 2.0: 57.0%. Both numbers place M2.7 in the open-weights frontier band on real-world software engineering.
- Pricing on platform: aggressive — MiniMax has been positioning M2 / M2.5 / M2.7 as the cheapest agentic API on a $-per-task basis.
Availability
- Weights on Hugging Face (
MiniMax-M2.7); hosted API on minimax.io and on partner providers (NVIDIA, Together AI). Modified MIT-style license.
Mistral AI
Mistral Medium 3.5 + Vibe Remote Agents
Overview
- First Mistral flagship since the company drew on its €830M GPU-buildout loan — Mistral Medium 3.5 ships as a dense 128B model with a 256k context window, released under a modified MIT license, in public preview.
- Positioning is unusual: Mistral Medium 3.5 is a single set of weights that replaces both Magistral (chat / reasoning) and Devstral 2 (coding) — the "merged flagship" framing. A per-request
reasoning_effortknob picks the right depth for the call. - Companion launch: Vibe remote agents — cloud-hosted async coding sessions spawnable from CLI or Le Chat, with the ability to "teleport" a local CLI session into the cloud mid-task.
Architecture
- Dense 128B transformer (no MoE in this generation), 256k context. Mistral has not disclosed attention variant, position encoding, or tokenizer details in the launch post.
- Per-request reasoning effort flag exposed via API — same single weights serve fast chat (low effort) and long agentic coding runs (high effort), instead of routing to a separate "thinking" model.
Post-training
- Merged-flagship recipe.
- Problem. Mistral previously shipped Magistral and Devstral as separate fine-tunes — two model lines to ship, host, and update, with users juggling routing.
- Mechanism. A single base is fine-tuned with a multi-task SFT + RL recipe that mixes chat reasoning data with the Devstral coding / agent data, then a single set of weights is released. The reasoning-effort flag controls the amount of internal chain-of-thought spent per request.
- Why. Eliminates the operational overhead of two model lines; lets shared representations between chat reasoning and coding reinforce each other rather than diverging during specialization.
Evaluation & Results
- SWE-Bench Verified: 77.6%, ahead of Devstral 2 and Qwen3.5 397B per the launch post.
- Trails Claude Opus 4.7 and DeepSeek-V4-Pro-Max (80.6%) on SWE-Bench Verified but on a 128B dense model, which is the implicit competitive frame.
Availability
- Open weights under modified MIT, public preview on La Plateforme, integrated as default in Vibe CLI. Devstral 2 deprecated; Magistral retired from Le Chat.
Moonshot AI
Kimi K2.6: Long-Horizon Coding & Agent Swarms
Overview
- 1T-parameter MoE / 32B active, 262,144-token context, native INT4 quantization at release. Modified MIT license. Four product variants from single-shot chat up to 300-agent parallel swarms.
- Three named contributions: Long-Horizon Coding training, Coding-Driven Design (visual → UI / full-stack), and Elevated Agent Swarm orchestration scaling to 300 sub-agents executing 4,000 coordinated steps.
- No standalone technical report yet — the blog and model card carry the technical content as of April 22, 2026.
Architecture
- 1T total / 32B active MoE — same parameter / activation ratio band as DeepSeek-V3 / V4-Flash. 262k context. Native INT4 quantization built into the weight release, so the model serves at INT4 by default rather than as a post-hoc quant.
Post-training
- Elevated Agent Swarm.
- Problem. Single-agent long-horizon coding runs hit context limits and degrade on tasks with parallel structure (refactor 200 modules, run a large test matrix). Naive multi-agent setups either contend for shared state or fail to coordinate.
- Mechanism. A controller K2.6 instance spawns up to 300 sub-agents that share a structured task DAG and a coordination protocol. Each sub-agent has its own context, and the controller reconciles their outputs across up to 4,000 coordinated steps. The model is trained on synthetic multi-agent rollouts where the reward depends on collective task completion, not individual sub-agent success.
- Why. Parallelizable software work (linting, codemods, cross-module refactors) was already amenable to embarrassingly parallel agent calls; the swarm protocol adds explicit coordination, which is what unlocks 4,000-step horizons without context blowup.
- Coding-Driven Design. Takes UI screenshots, sketches, or text prompts and produces shippable interfaces and lightweight full-stack scaffolds. Trained with paired (visual input → working code) data and an executable-correctness reward.
Evaluation & Results
- Moonshot's launch numbers position K2.6 in the same agentic-coding band as DeepSeek-V4-Flash and MiniMax M2.7 — not pulled out as standalone tables in the blog. Marktechpost coverage emphasizes long-horizon coding gains over K2.5 as the headline delta.
Availability
- Weights on Hugging Face (
moonshotai/Kimi-K2.6). Hosted API on kimi.com and on Cloudflare Workers AI from launch.
OpenAI
GPT-5.5 System Card
Overview
- GPT-5.5 Thinking and GPT-5.5 Pro launched April 23, 2026. API access withheld until April 24 pending separate safeguards, then opened the same day after the system card was updated to cover deployment specifics.
- OpenAI's positioning: model "designed for complex, real-world work — writing code, researching online, analyzing information, creating documents and spreadsheets, and moving across tools." The framing emphasizes early task understanding, lower prompting overhead, and self-verification — the same agentic competencies the rest of the wave is competing on.
- Not available to free-tier users at launch.
Architecture
- Not disclosed. OpenAI's system cards under the Preparedness framework do not publish architecture / parameter counts.
Post-training
- OpenAI ran the full Preparedness Framework evaluation suite plus targeted external red-teaming for advanced cybersecurity and biology capabilities prior to deployment.
- Feedback collected from approximately 200 early-access partners on real-world use cases before public release.
- Safeguards described as OpenAI's "strongest set to date," with emphasis on preserving legitimate beneficial use of the underlying capabilities.
Evaluation & Results
- The system card emphasizes capability gains in coding, online research, document / spreadsheet authoring, and multi-tool workflows. OpenAI claims earlier task understanding, less prompting overhead, more effective tool use, and self-verification ("checks its work and keeps going until it's done").
- Specific benchmark numbers in the system card are dominated by Preparedness-style cyber and biology evals rather than the public agentic-coding leaderboards; comparative SWE-Bench / Terminal-Bench numbers are sparser in OpenAI's own release artifacts than in third-party coverage.
Safety & Limitations
- API access was deliberately staggered — model in ChatGPT first, API behind it by one day — to validate the safeguards in the lower-API-leverage product before opening developer access. This is the operational pattern OpenAI has adopted since the GPT-5 launch.
Availability
- GPT-5.5 Thinking and GPT-5.5 Pro on ChatGPT (paid tiers only at launch) and on the OpenAI API as of April 24, 2026.
xAI
Grok 4.3
Overview
- xAI dropped Grok 4.3 in beta on April 17 with no press release; rolled the full API to GA on April 30, 2026.
- Three feature lines define the release: 1M-token context, native video input up to 5 minutes at 1080p (MP4 / MOV / WebM), and native PDF / PPTX / XLSX output straight from a prompt.
- Pricing: $1.25 / $2.50 per million input / output tokens — roughly a 40% input cut and 60% output cut versus Grok 4.20.
Architecture
- Not disclosed in the launch artifacts. xAI's release notes are product-feature-shaped, not technical-report-shaped.
Evaluation & Results
- Artificial Analysis places Grok 4.3 just above Muse Spark and Claude Sonnet 4.6 on their Intelligence Index, and 4 points ahead of Grok 4.20 0309 v2.
- Largest single-benchmark delta: GDPval-AA Elo of 1500, up 321 points from Grok 4.20 0309 v2's 1179.
- Voice cloning is shipped as a separate "fast, powerful" suite alongside Grok 4.3 — VentureBeat covers it as a distinct product surface rather than as part of the core 4.3 model.
Availability
- API endpoints documented at docs.x.ai. Beta during the April 17 → April 30 window; GA on April 30.