Flow Map Distillation
TL;DR
Focus
One Tier 2 frontier-lab paper qualified after dedup in the 36-hour window: AnyFlow from NVIDIA Research and NUS Show Lab (arXiv:2605.13724, submitted Wed, 13 May 2026 16:06 UTC). The paper introduces the first any-step video diffusion distillation framework based on flow maps, replacing the consistency-distillation objective with flow-map transition learning over arbitrary time intervals and adding an on-policy distillation procedure called Flow Map Backward Simulation. No Tier 1 flagship launches and no other qualifying Tier 2/3 frontier-lab papers surfaced from the May 12–14 window after dedup against prior reviews; the May 11 Qwen-Image-2.0 launch and the May 12 A²RD / Fast-BLT / LPO papers are covered upstream.
Competitiveness
The relevant axis is open-weights video diffusion distillation under any-step inference. AnyFlow targets the regime where consistency-distilled models (CM, sCM, rCM, Self-Forcing) sit on top of strong flow-matching teachers such as Wan2.1-T2V-1.3B and Wan2.1-T2V-14B, and a parallel line of community-distilled checkpoints (Krea-Realtime-Wan2.1-14B, LightX2V-Wan2.1-14B-CausVid, FastVideo-CausalWan2.2-A14B-Preview). On the bidirectional Wan2.1-T2V-14B backbone, AnyFlow matches or surpasses rCM in the few-step regime and continues to improve quality as more sampling steps are allocated — the test-time scaling axis where consistency-distilled models degrade. On the causal FAR-Wan2.1-14B backbone, AnyFlow-FAR at 4 NFEs reaches I2V quality comparable to the undistilled Wan2.1-I2V-14B teacher at 50×2 NFEs, and beats the three community 14B consistency-distilled baselines on T2V. The closed-source frontier on video generation is Veo 3 (Google DeepMind), Sora 2 (OpenAI), and Kling 2.5 (Kuaishou); AnyFlow does not benchmark against these — the comparison is within the open Wan-family ecosystem and against prior distillation paradigms.
New frontier releases
No new flagship model launches in the past 36 hours. The latest LLM-side flagships remain GPT-5.5 (April 23), Claude Opus 4.7 (April 16), DeepSeek-V4 (April 24), and Grok 4.3 (May 6); the latest image-generation flagship is Qwen-Image-2.0 (May 11) — all covered upstream.
NVIDIA
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
Overview
- Authors: Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai, Mike Zheng Shou. Affiliations: NVIDIA (Yuchao Gu, Song Han, Han Cai), NUS Show Lab (Guian Fang, Yuxin Jiang, Weijia Mao, Mike Zheng Shou), MIT (Song Han). Corresponding authors: Han Cai (NVIDIA), Mike Zheng Shou (NUS). cs.CV (cross-listed cs.AI); v1 submitted Wed, 13 May 2026 16:06:34 UTC; 31.8 MB v1 with embedded comparison videos.
- Code at github.com/NVlabs/AnyFlow under Apache 2.0; model collection at huggingface.co/collections/nvidia/anyflow; project page nvlabs.github.io/AnyFlow; Gradio demo provided. Four checkpoints released:
AnyFlow-Wan2.1-T2V-1.3B-Diffusers,AnyFlow-Wan2.1-T2V-14B-Diffusers,AnyFlow-FAR-Wan2.1-1.3B-Diffusers,AnyFlow-FAR-Wan2.1-14B-Diffusers. - Two architectures supported in one distillation recipe: bidirectional video diffusion (Wan2.1-T2V backbone) and causal video diffusion (FAR-Wan2.1 backbone, where FAR is the authors' prior next-frame-prediction work, arXiv:2503.19325). On the causal backbone the same checkpoint handles T2V, I2V, and V2V.
- Two named contributions in the paper: AnyFlow itself — the flow-map distillation framework — and Flow Map Backward Simulation, the on-policy distillation procedure that makes flow-map distillation tractable at video scale. Both are explained in Methodology below.
Methodology
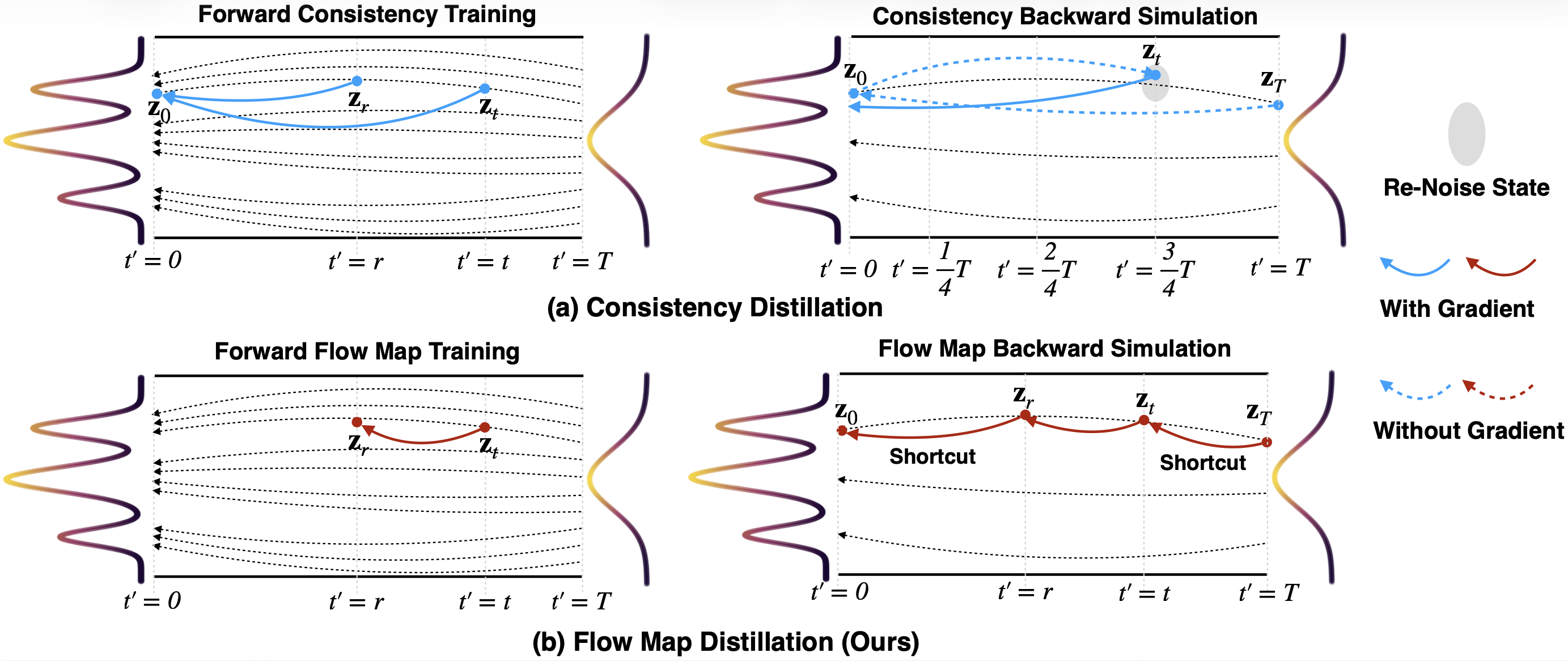
- Mechanism — AnyFlow: flow-map distillation in place of consistency distillation.
- Problem. Consistency-distilled few-step video models (CM, sCM, rCM, Self-Forcing on top of flow-matching teachers like Wan2.1-T2V) degrade as more sampling steps are added at inference; throwing more compute at them stops helping past 4–8 NFEs. The cause is that consistency distillation forces the student to learn the endpoint map zt → z0, so at inference the model can only re-traverse a consistency-sampling trajectory rather than the original probability-flow ODE trajectory, which is what gives flow matching its smooth test-time scaling.
- Mechanism. AnyFlow shifts the distillation target from the endpoint consistency mapping (zt → z0) to an arbitrary two-time flow-map transition (zt → zr) for any pair of timesteps t > r ≥ 0. A forward-training stage initializes the student to predict zr from zt at arbitrary (t, r) pairs sampled across the trajectory. At inference, the student can be run for any number of Euler steps along the original ODE schedule by composing flow-map transitions: 1-step (z1→z0), 4-step, 16-step, 32-step — the same checkpoint serves all budgets.
- Why. Because the student now models the full instantaneous flow field over the ODE trajectory, not just the endpoint shortcut, the test-time scaling property of flow matching is preserved: more sampling steps continue to reduce discretization error rather than fighting a learned consistency-sampling trajectory. It beats consistency distillation on the axis consistency distillation cannot improve on — the ≥16-NFE regime — while matching it in the 4-NFE regime. It also makes downstream fine-tuning tractable: because the flow field is preserved, the distilled checkpoint can be continued-trained on a specialized dataset without losing few-step sampling (see the I2V identity-preservation and trajectory-accuracy improvements on the downstream pipeline in Figure 3).
- Mechanism — Flow Map Backward Simulation for on-policy distillation.
- Problem. Forward-training a flow-map student on offline (t, r, zt, zr) tuples sampled from the teacher gives an off-policy signal: at inference the student rolls out its own trajectory and accumulates errors the teacher never showed it — discretization error in few-step sampling and exposure bias in causal generation. Naive on-policy distillation would require unrolling the full Euler trajectory through the student and backpropagating through every step, which is prohibitively expensive at 1.3B–14B video scale.
- Mechanism. Flow Map Backward Simulation decomposes a full Euler rollout into shortcut flow-map transitions. Instead of running every intermediate Euler step, the student takes large flow-map jumps along the trajectory; each jump is a single forward call but covers many ODE steps. The procedure is on-policy — the rollout is the student's own trajectory — but the per-rollout cost is bounded by the number of shortcut segments, not the number of Euler steps. The result is a backward simulation that exposes the student to its own discretization/exposure errors and lets the flow-map objective correct them with tractable compute.
- Why. Versus consistency distillation's on-policy phase (which replaces the Euler trajectory with a consistency-sampling trajectory and uses a truncated gradient), Flow Map Backward Simulation preserves the Euler trajectory — that is exactly what keeps the test-time scaling property. The shortcut decomposition is what makes it cheap enough to apply at 14B parameters. The procedure is the bridge between “train a flow-map student” (which is just a different loss) and “train a flow-map student that actually exceeds consistency baselines at video scale” (which requires on-policy supervision under a tractable compute budget).
- Training pipeline: (1) forward-training initialization to learn zt → zr across the trajectory, then (2) Flow Map Backward Simulation as the on-policy distillation phase. Implementation is on top of the diffusers codebase with components from FAR (causal next-frame prediction) and Self-Forcing (causal consistency-distillation baseline).
- Training scale validated from 1.3B to 14B parameters across both bidirectional and causal architectures.
Evaluation & results
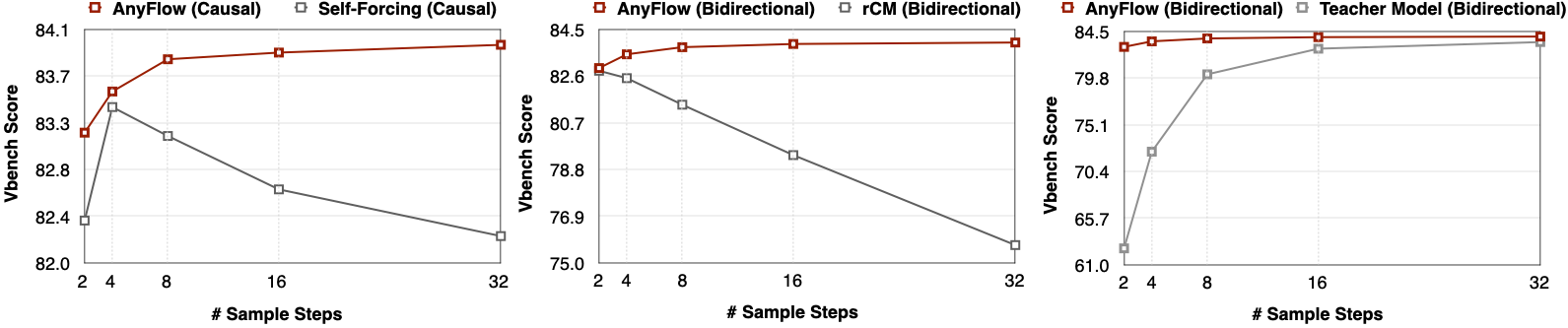
- Test-time scaling vs. flow-matching teacher. AnyFlow uniformly lifts performance across the entire sampling trajectory, improving over the flow-matching teacher at every step budget. The largest gains are in the few-step regime, but unlike consistency baselines AnyFlow continues to scale upward as NFEs grow.
- Test-time scaling vs. consistency distillation (rCM). AnyFlow matches or surpasses rCM at 4 NFEs and preserves the flow-matching test-time scaling behavior, where rCM stagnates or degrades. This is the headline behavioral claim of the paper.
- Causal 14B T2V. AnyFlow-FAR-Wan2.1-14B at 4 NFEs is reported by the project page to achieve better dynamics and overall quality than the three community causal-distillation baselines on the same backbone family: Krea-Realtime-Wan2.1-14B (4 NFEs), LightX2V-Wan2.1-14B-CausVid (9 NFEs), FastVideo-CausalWan2.2-A14B-Preview (8 NFEs). The qualitative T2V comparison gallery includes scenes with global camera motion (Eiffel Tower aerial), human-body articulation (male sprinter), and high-frequency dynamics (gameplay sequences).
- Causal 14B I2V. Within the same checkpoint, AnyFlow-FAR-Wan2.1-14B supports I2V at 4 NFEs with quality comparable to the undistilled Wan2.1-I2V-14B teacher at 50×2 NFEs — roughly a 25× reduction in sampling cost at parity.
- Causal 14B V2V. Same checkpoint also supports V2V at 4 NFEs — one model, three tasks (T2V/I2V/V2V), which is what the “multiple tasks” claim in the GitHub overview refers to.
- Bidirectional 14B T2V. AnyFlow-Wan2.1-T2V-14B at 4 NFEs vs. rCM-Wan2.1-T2V-14B at 4 NFEs — qualitative comparisons show better motion coherence and identity stability on the gameplay, suit-and-tie portrait, astronaut, tropical-fish, and horse-riding prompts.
- Evaluation harness is VBench (T2V + I2V); training data uses the VidProm corpus (a public dummy subset,
dc-ai/vidprom_dummy, is released alongside the code for reproducibility). - The arXiv report does not publish a head-to-head table of VBench scores in the abstract; the quantitative comparison is rendered in the paper's Figure 2 (test-time scaling curves). Specific VBench numbers should be read from the PDF itself; this review preserves the project-page claims verbatim and does not invent score values.
Ablations
- Distillation target. Replacing the endpoint consistency mapping (zt → z0) with the arbitrary two-time flow-map transition (zt → zr) is the paper's single biggest design lever — the flow-map student is what restores the upward test-time scaling shape that consistency students lose. The paper frames this as the central paradigm shift; the project page summarizes it in the Figure 1 paradigm-comparison diagram.
- On-policy vs. off-policy. Pure forward-training (off-policy) is the initialization; Flow Map Backward Simulation is the on-policy refinement. The paper attributes the closing of the few-step quality gap with rCM to the on-policy phase, with the rationale that without on-policy exposure the student does not see its own discretization / exposure errors.
- Shortcut decomposition. Decomposing the full Euler rollout into shortcut flow-map transitions is what keeps the on-policy phase tractable at 14B. Without it, on-policy flow-map distillation would require backpropagating through every Euler step.
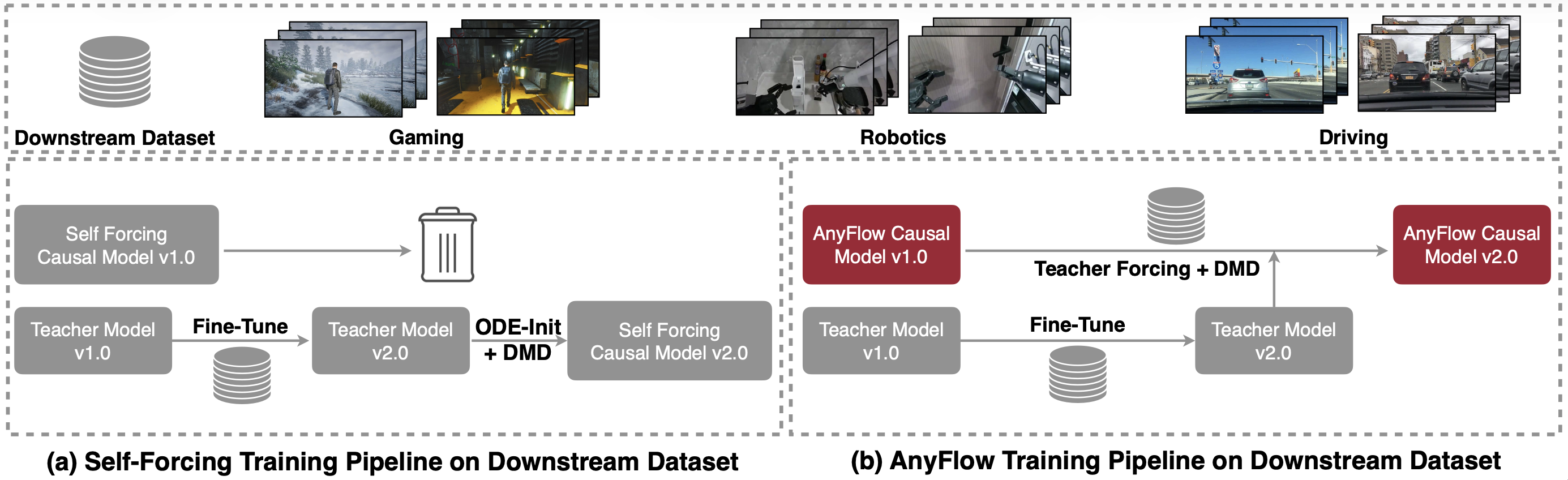
- Downstream continued training. The flow map formulation preserves a fine-grained instantaneous flow field, so the distilled checkpoint can be continued-trained on a specialized I2V dataset while keeping 4-NFE sampling. Reported gains: identity preservation (e.g. robot-arm type stays fixed across frames) and trajectory accuracy (e.g. moving pedestrians follow physical paths). This is the property that consistency-distilled checkpoints lose — once collapsed to endpoint mapping, they cannot easily be fine-tuned without re-distilling.
Other
- License: Apache 2.0 for code; HuggingFace model collection under the
nvidiaorg. - Builds directly on three prior works: diffusers (codebase), FAR (causal next-frame prediction backbone, also from Show Lab; arXiv:2503.19325), and Self-Forcing (causal consistency-distillation baseline). Also references TiM.
- Backbones distilled in this paper:
Wan2.1-T2V-1.3B,Wan2.1-T2V-14B, plus FAR-Wan2.1 variants. Wan is Alibaba's open-source video diffusion family; AnyFlow is not a new backbone but a new distillation recipe applied to existing strong teachers. - Limitation noted by the abstract framing: the paper validates the flow-map paradigm on video diffusion but does not claim generality to other diffusion-distillation regimes (image diffusion, audio diffusion, molecular diffusion); whether Flow Map Backward Simulation transfers cleanly to those modalities is an open question.